
Stock Memo
[빅데이터분석기사] 분석 방안 수립, 데이터 분석 방안 본문

1. 분석 방법론
데이터 분석시 품질확보를 위하여 단계별로 수행해야 하는 활동, 작업, 산출물을 정의한다.
- 프로젝트는 한 개인의 역량이나 조직의 우연한 성공에 의해서는 안 되고 일정 품질 수준 이상의 산출물과 프로젝트의 성공 가능성을 제시해야 한다.
<분석 방법론의 구성요건>
- 상세한 절차(Procedures)
- 방법(Methods)
- 도구와 기법(Tools & Techniques)
- 템플릿과 산출물(Templates & Outputs)
- 어느 정도의 지식만 있으면 활용 가능한 수준의 난이도
<분석 방법론의 생성과정(선순환 과정)>
| 형식화 | 개인의 암묵지가 조직의 형식지로 발전되었다. 분석가의 경험을 바탕으로 정리하여 문서화한다. |
| 체계화 | 문서화한 최적화된 형식지로 전개됨으로써 방법론이 생성되었다. 문서에는 절차나 활동 및 작업, 산출물, 도구 등을 정의한다. |
| 내재화 | 개인에게 전파되고 활용되어 암묵지로 발전되었다. 전파된 방법론을 학습하고 활용하여 내재화한다. |
2. 계층적 프로세스 모델 구성
분석 방법론은 일반적으로 계층적 프로세스 모델 형태로 구성 가능하며, 단계, 데스크, 스텝 3계층으로 구성된다.
<최상위 계층 - 단계(Phase)>
- 프로세스 그룹을 통하여 완성된 단계별 산출물을 생성한다.
- 각 단계는 기준선으로 설정되어 관리되어야 하며 버전관리 등을 통하여 통제한다.
<중간 계층 - 태스크(Task)>
- 각 태스크는 단계를 구성하는 단위 활동이다.
- 물리적 또는 논리적 단위로 품질검토가 가능하다.
<최하위 계층 - 스텝(Step)>
- WBS(Work Breakdown Structure)의 워크패키지(Work Package)이다.
- 입력자료, 처리 및 도구, 출력자료로 구성된 단위 프로세스이다.

3. 소프트웨어개발생명주기 활용
분석 방법론은 소프트웨어 공학의 소프트웨어개발생명주기를 활용항 구성할 수도 있다.
- 소프트웨어개발생명주기(SDLC: Software Development Life Cycle)는 소프트웨어에 대해 요구분석과 설계, 구현과정을 거쳐 설치, 운영과 유지보수, 그리고 폐기할 때까지의 전 과정을 가시적으로 표현한 것이다.
▶ 소프트웨어개발생명주기의 구성요소
| 계획 (요구명세) |
고객의 요구사항을 명세화한다. 타당성 조사 및 소프트웨어의 기능과 제약조건을 정의하는 명세서를 작성한다. 요구사항은 일반적으로 모호하고 불완전하며 모순되기도 한다. |
| 요구분석 | 대상이 되는 문제 영역과 사용자가 원하는 Task를 이해한다. |
| 설계 | 분석모형을 가지고 이를 세분화함으로써 구현될 수 있는 형태로 전환한다. |
| 구현 | 실행 가능한 코드를 생성한다. |
| 시험 | 발생가능한 실행 프로그램의 오류를 발견하고 수정한다. |
| 유지보수 | 인수가 완료된 후 일어나는 모든 개발 활동이다. |
<폭포수 모형(Waterfall Model)> : 고전적 Life Cycle Paradigm으로 분석, 설계, 개발, 구현, 시험 및 유지보수 과정을 순차적으로 접근하는 방법이다.
| 소프트웨어 개발을 단계적, 순차적, 체게적 접근 방식으로 수행한다. 개념 정립에서 구현까지 하향식 접근 방법을 사용한다. 전 단계의 산출물은 다음 단계의 기초가 된다. 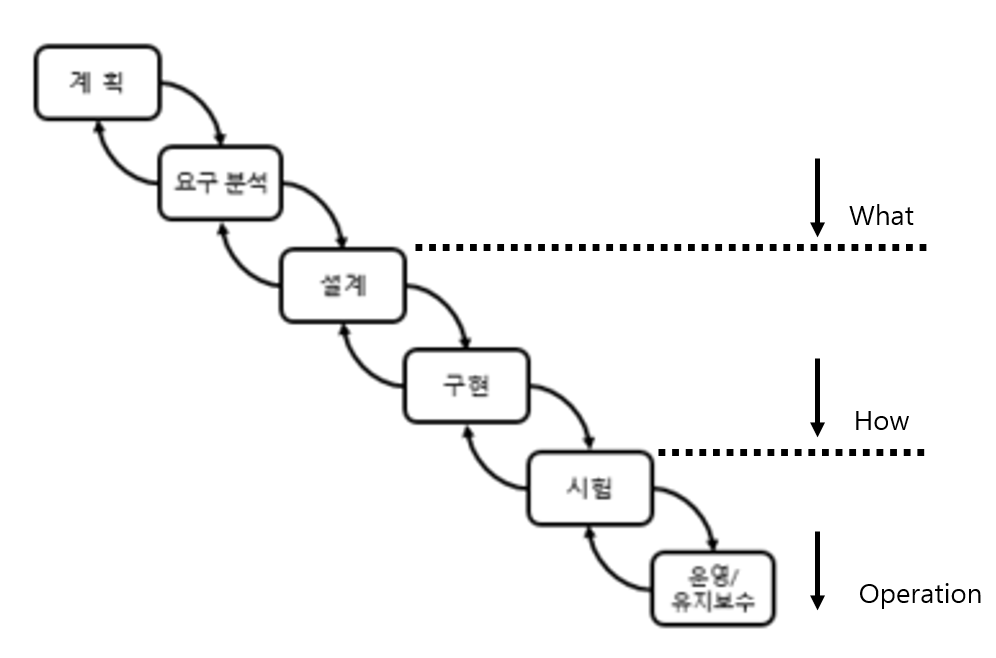 |
<프로토타입 모형(Prototype Model)> : 사용자의 요구사항을 충분히 분석할 목적으로 시스템의 일부분을 일시적으로 간략히 구현한 다음 다시 요구사항을 반영하는 과정을 반복하는 개발모형이다.
- 실험적 프로토타입 : 요구분석의 어려움을 해결하기 위해 실제 개발된 소프트웨어의 일부분을 직접 개발함으로써 의사소통의 도구로 활용한다.
- 진화적 프로토타입 : 프로토타입을 요구분석의 도구로만 활용하는 것이 아니라, 이미 개발된 프로토타입을 지속적으로 발전시켜 최종 소프트웨어로 발전시킨다.
| 요구 분석의 어려움 해결을 통해 사용자의 참여를 유도한다. 요구사항 도출과 이해에 있어 사용자와의 커뮤니케이션 수단으로 활용 가능하다. 사용자 자신이 원하는 것이 무엇인지 구체적으로 잘 모르는 경우 간단한 시제품으로 개발할 수 있다. 개발 타당성을 검토하는 수단으로 활용할 수 있다.  |
<나선형 모형(Spiral Model)> : 시스템을 개발하면서 생기는 위험을 최소화하기 위해 나선을 돌면서 점진적으로 완벽한 시스템으로 개발하는 모형이다.
| 프로젝트의 완전성 및 위험 감소와 유지보수가 용이하다. 관리가 중요하나 매우 어렵고 개발시간이 장기화될 가능성이 있다. 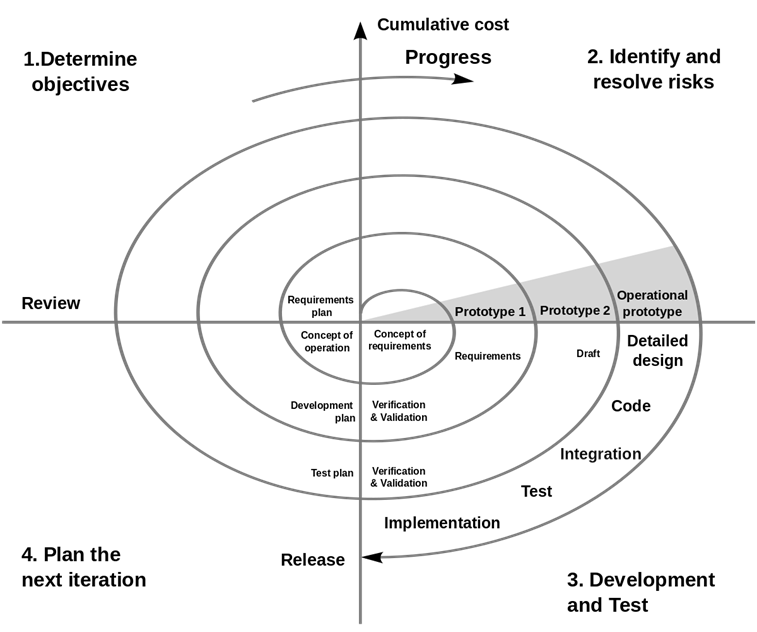 |
<반복적 모형(Iterative Development Model)> : 사용자의 요구사항 일부분 혹은 제품의 일부분을 반복적으로 개발하여 최종 시스템으로 완성하는 모형이다.
- 증분형 모형(Incremental Model) : 사용자 요구사항과 제품의 일부분을 반복적으로 개발하며 대상범위를 확대해 나아가서 최종제품을 완성하는 방법이다.
| - 증첫 번째 검증은 핵심제품, 몇 사람만으로 구현 가능하다. 프로토타입 모형과 같이 반복적이나 각 점증이 갖는 제품 인도에 초점을 두고 있다. 규모가 큰 개발 조직일 경우 자원을 각 증분 개발에 충분히 할당할 수 있어 각 증분의 병행 개발로 기간을 단축시킬 수 있다. 증분의 수가 많고 병행 개발이 빈번하게 이루어지면 관리가 어려워지고, PM은 증분 개발 홛동 간 조율에 많은 노력이 필요하다.  - 증분 1 : 소프트웨어 요구사항 중 1에 해당하는 프로토타입 개발 - 증분 2 : 소프트웨어 요구사항 중 2에 해당하는 프로토타입 개발 - 증분 n : 소프트웨어 요구사항 중 n에 해당하는 프로토타입 개발 - 정보흐름 : 각 프로토타입 개발과정에서 단계별로 타 프로토타입의 개발과정에 영향 |
- 진화형 모형(Evolution Model) : 시스템이 가지는 여러 구성요소의 핵심부분을 개발한 후 각 구성요소를 지속적으로 발전시켜 나가는 방법이다.
| 다음 단계로의 진화를 위해 전체 과정에 대한 개요가 필요하다. 프로토타입을 만들고 이를 다시 분석함으로써 요구사항을 진화시키는 방법이다. 프로토타입의 시스템은 재사용을 전재로 한다.  - 핵심교구사항 개발 : 소프트웨어 요구사항의 핵심적인 부분(프로토타입)을 개발 - 1단계 진화 : 핵심요구사항 개발과정에서 산출된 프로토타입을 재분석하여 요구사항 진화 - n단계 진화 : n-1의 요구사항 개발과정에서 산출된 프로토타입을 재분석하여 최종 완성 - Feedback : 각 단계의 프로토타입을 설치/운영하여 발생하는 요구사항들을 차기 개발에 반영 |
▶ 소프트웨어개발생명주기의 대표적 유형 비교
| 폭포수 모형 | 검토 및 승인을 거쳐 순차적, 하향식으로 개발이 진행된다. | ||
| 장점 | 이해하기 쉽고 관리가 용이하다. 다음 단계 진행 전에 결과를 검증한다. |
||
| 단점 | 요구사항 도출이 어렵다. 설계 및 코딩과 테스트가 지연된다. 문제점 발견이 늦어진다. |
||
| 원형 모형 | 시스템의 핵심적인 기능을 먼저 만들어 평가한 후 구현한다. | ||
| 장점 | 요구사항 도출과 시스템 이해가 용이하다. 의사소통을 향상시킨다. |
||
| 단점 | 사용자의 오해(완제품)가 발생하기 쉽다. 폐기되는 프로토타입이 존재한다. |
||
| 나선형 모형 | 폭포수 모형과 원형 모형의 장점에 위험분석을 추가하였다. | ||
| 구현 단계 |
계획수립 | 목표, 기능 선택, 제약조건을 설정한다. | |
| 위험분석 | 기능 선택의 우선순위 및 위험요소를 분석하고 제거한다. | ||
| 개발 | 선택된 시근을 개발한다. | ||
| 고객평가 | 개발 결과를 평가한다. | ||
| 장점 | 점증적으로 개발 시 실패 위험을 감소시킬 수 있다. 테스트가 용이하고 피드백이 있다. |
||
| 단점 | 관리가 복잡하다. | ||
| 반복적 모형 | 시스템을 여러 번 나누어 릴리즈하는 방법이다. | ||
| Incremental | 기능을 분해한 후 릴리즈별 기능을 추가 개발한다. | ||
| Evolution | 전체 기능을 대상으로 하되 릴리즈 진행하면서 기능이 완벽해진다. | ||
<소프트웨어개발생명주기 모형 선정 기준>
- 프로젝트의 규모와 성격
- 개발에 사용되는 방법과 도구
- 개발에 소요되는 시간과 비용
- 개발과정에서의 통제수단과 소프트웨어 산출물 인도 방식
4. KDD 분석 방법론
<KDD 분석 방법론의 9가지 프로세스>
- 분석 대상 비즈니스 도메인의 이해
- 분석 대상 데이터셋 선택과 생성
- 데이터에 포함되어 있는 잡음(Noise)과 이상값(Outlier) 등을 제거하는 정제작업이나 선처리
- 분석 목적에 맞는 변수를 찾고 필요시 데이터의 차원을 축소하는 데이터 변경
- 분석 목적에 맞는 데이터 마이닝 기법 선택
- 분석 목적에 맞는 데이터 마이닝 알고리즘 선택
- 데이터 마이닝 시행
- 데이터 마이닝 결과에 대한 해석
- 데이터 마이닝에서 발견된 지식 활용
<KDD 분석 방법론의 분석절차>
| 단계 | 내용 | |
| 1 | 데이터셋 선택 (Selection) |
분석대상 비즈니스 도메인에 대한 이해 및 프로젝트 목표의 정확한 설정을 선행한다. 데이터베이스 또는 윈시 데이터에서 분석에 필요한 데이터를 선택한다. 필요 시에 목표 데이터를 추가적으로 구성하여 활용한다. |
| 2 | 데이터 전처리 (Preprocessing) |
잡음(Noise)과 이상값(Outlier), 결측치(Missing Value)를 식별하고 필요시 제거하거나 대체한다. 데이터가 추가적으로 필요한 경우 데이터셋 선택 절차부터 다시 실행한다. |
| 3 | 데이터 변환 (Transformation) |
분석 목적의 맞는 변수를 선택하거나 데이터의 차원 축소 등을 수행한다. 학습용 데이터와 검증용 데이터로 데이터를 분리한다. |
| 4 | 데이터 마이닝 (Data Mining) |
분석 목적에 맞는 데이터 마이닝 기법 및 알고리즘을 선택하여 분석을 수행한다. 필요 시 데이터 전처리와 데이터 변환 절차를 추가로 실행하여 데어터 분석 결과의 품질을 높일 수 있다. |
| 5 | 데이터 마이닝 결과 평가 (Interpretaion/ Evaluation) |
분석 결과에 대한 해석과 평가 및 분석 목적과의 일치성을 확인한다. 발견된 지식을 업무에 활용하기 위한 방안을 모색한다. 필요한 경우 데이터셋 선택부터 데이터 마이닝 절차까지 반복하여 수행한다. |

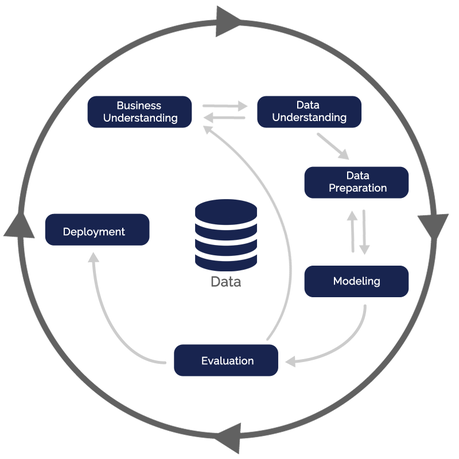
5. CRISP-DM 분석 방법론
CRISP-DM(Cross Industry Standard Process for Data Mining)은 계층적 프로세스 모델로써 4계층으로 구성된 데이터 마이닝 프로세스이다.
- 비즈니스 요구사항에 맞게 데이터 마이닝을 반복적으로 수행할 수 있다.
<CRISP-DM 분석 방법론의 4계층>
- 최상위 레벨 : 여러 개의 단계(Phases)로 구성된다.
- 일반화 태스크(Generic Tasks) : 데이터 마이닝의 단일 프로세스를 완전하게 수행하는 단위이다.
- 세분화 태스크(Specialized Tasks) : 일반화 태스크를 구체적으로 수행한다.
- 프로세스 실행(Process Instances) : 데이터 마이닝을 구체적으로 실행한다.

<CRISP-DM 분석 방법론의 분석절차>
| 단계 | 내용 | 세부업무 |
| 업무 이해 (Business Understanding) |
비즈니스 관점에서 프로젝트의 목적과 요구사항을 이해하기 위한 단계이다. 도메인 지식을 데이터 분석을 위한 문제 정의로 변경한다. 초기 프로젝트 계획을 수립한다. |
업무 목적 파악 상황 파악 데이터 마이닝 목표 설정 프로젝트 계획 수립 |
| 데이터 이해 (Data Understanding) |
분석을 위한 데이터 수집 및 데이터 속성을 이해한다. 데이터 품질 문제를 식별한다. 인사이트를 발견하는 단계이다. |
초기 데이터 수집 데이터 기술 분석 데이터 탐색 데이터 품질 확인 |
| 데이터 준비 (Data Preparation) |
수집된 데이터를 분석 기법에 적합한 데이터로 변환한다. | 분석용 데이터셋 선택 데이터 정제 분석용 데이터셋 편성 데이터 통합 데이터 포맷팅 |
| 모델링 (Modeling) |
다양한 모델링 기법과 알고리즘으로 모형 파라미터를 최적화한다. 모델링 결과를 테스트용 프로세스와 데이터셋르오 평가하여 모형 과적합 등의 문제를 확인한다. 데이터셋을 추가하기 위해 데이터 준비 절차를 반복할 수 있다. |
모델링 기법 선택 모형 테스트 계획 설게 모형 작성 모형 평가 |
| 평가 (Evaluation) |
분석 모형이 프로젝트의 목적에 부합 하는지 평가한다. 데이터 마이닝 결과를 수용할 것인지 최종적으로 판단한다. |
분석결과 평가 모델링 과정 평가 모형 적용성 평가 |
| 전개 (Deployment) |
완성된 분석 모형을 업무에 적용하기위한 계획을 수립한다. 모니터링과 분석 모형의 유지보수 계획을 마련한다. 프로젝트 종료 관련 프로세스를 수행하여 프로젝트 완료한다. |
전개 계획 수립 모니터링과 유지보수 계획 수립 프로젝트 종료 보고서 작성 프로젝트 리뷰 |
<KDD 분석 방법론과의 비교>
| CRISP-DM 분석 방법론 | KDD 분석 방법론 |
| 업무 이해(Business Understanding) | - |
| 데이터 이해(Data Understanding) | 데이터셋 선택(Selection) |
| 데이터 전처리(Preprocessing) | |
| 데이터 준비(Data Preparation) | 데이터 변환(Transformation) |
| 모델링(Modeling) | 데이터 마이닝(Data Mining) |
| 평가(Evaluation) | 데이터 마이닝 결과 평가 (Interpretation/Evaluation) |
| 전개(Deployment) | - |
6. SEMMA 분석 방법론
SEMMA(Sample, Explore, Modify, Model and Assess)는 SAS Institute의 주도로 만들어진 기술과 통계 중심의 데이터 마이닝 프로세스이다.
<SEMMA 분석 방법론의 특징>
- SAS Institute의 데이터 마이닝 도구와 손쉽게 접목하여 활용할 수 있다.
- 주로 데이터 마이닝 프로젝트의 모델링 작업에 중점을 두고 있다.
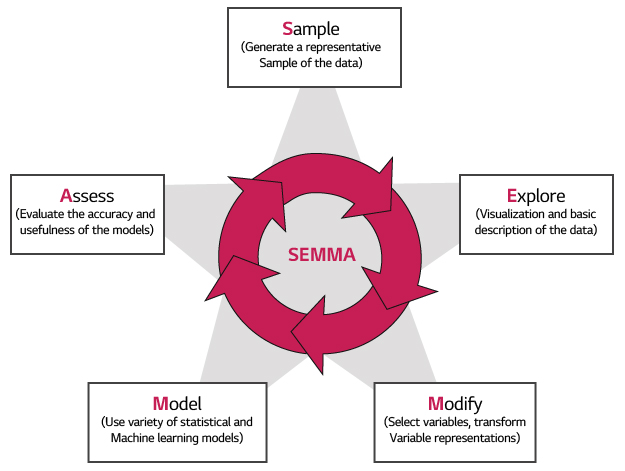
<SEMMA 분석 방법론의 분석 절차>
| 단계 | 내용 | 세부요소/산출물 |
| 추출 (Sample) |
분석할 데이터 추출 모델을 평가하기 위한 데이터 준비 |
통계적 추출 조건 추출 |
| 탐색 (Explore) |
분석용 데이터 탐색 데이터 오류 확인 비즈니스 이해 이상 현실 및 변화 탐색 |
그래프 기초통계 Clustering 변수 유의성 및 상관분석 |
| 수정 (Modify) |
분석용 데이터 변환 데이터 표현 극대화(시각화) |
수량화 표준화 변환 그룹화 |
| 모델링 (Model) |
분석 모델 구축 패턴 발견 모델링과 알고리즘의 적용 |
Neural Network Decision Tree Logistic Regression 통계기법 |
| 평가 (Assess) |
모델 평가 및 검증 서로 다른 모델 동시 비교 Next Step 결정 |
Report Feedback 모델 검증 자료 |
'공부 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사] 분석 작업 계획, 분석 작업 개요 (0) | 2021.08.31 |
|---|---|
| [빅데이터분석기사] 분석 방안 수립, 빅데이터 분석 방법론 (0) | 2021.08.30 |
| [빅데이터분석기사] 분석 방안 수립, 분석 문제 정의 개요 (0) | 2021.08.30 |
| [빅데이터분석기사] 분석 방안 수립, 분석 마스터 플랜과 로드맵 설정 (0) | 2021.08.13 |
| [빅데이터분석기사] 분석 방안 수립, 데이터 분석 기획 (1) | 2021.08.13 |



